




Most institutions can assemble a first version of the register. The pressure comes later, when that register has to survive supervisory ingestion.
Article 28(3) of Regulation (EU) 2022/2554 creates the obligation to maintain the register of information under the Digital Operational Resilience Act (DORA), and Commission Implementing Regulation (EU) 2024/2956 turns that obligation into a structured reporting exercise with defined templates and fill-in instructions.
A common mistake is to treat submission as the last administrative step. It is really the first technical check on whether the register has been built properly.
What is actually submitted: package, not tables
In DORA Register of Information (RoI) reporting, supervisors receive a structured reporting package — a ZIP with metadata and linked comma-separated values (CSV) files — not individual exported tables. The European Banking Authority’s (EBA) package guidance for preparing plain CSV reporting for DORA requires plain-csv, with eXtensible Business Reporting Language JSON (xBRL-JSON) metadata used for validation.
A minimum viable package contains these parts:
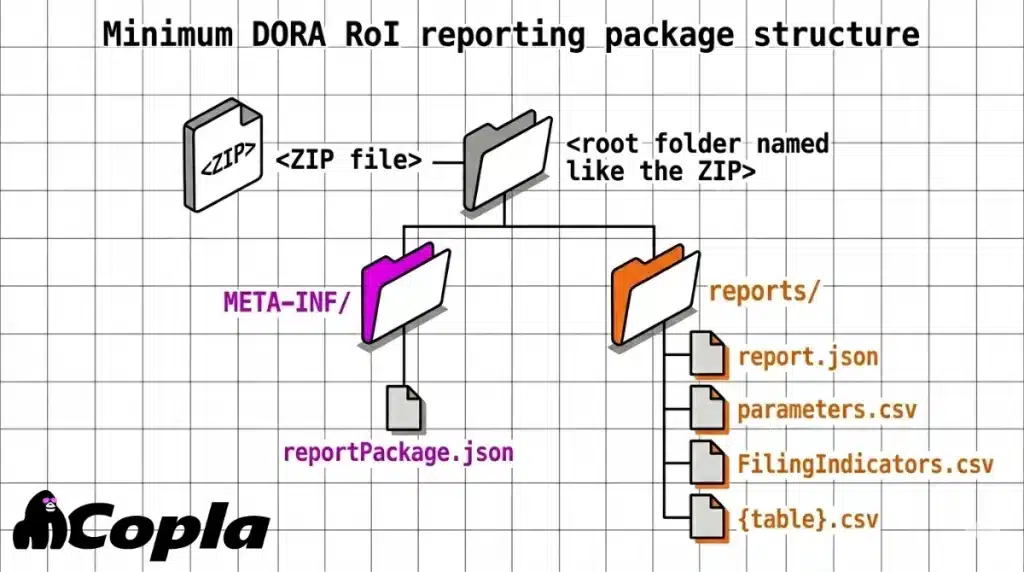
This is where institutions often lose ground before validation has even started.
A wrong root folder name or a mismatch between the ZIP name and the internal folder can stop ingestion before a single business rule is touched. That is also why passing template checks does not mean the dataset satisfies reporting logic.
Wrong module, wrong entry point, fast rejection
Package naming and entry-point alignment
Versioning errors are rarely interesting, but they are expensive — they fail early and make everything after them harder to read.
report.json has to point to the published entry point for the exact framework, module and version combination in the EBA Reporting Framework 4.0 technical package, and the ZIP name has to line up with the same reporting cycle. For the first 2025 cycle, the FAQ naming convention for DORA RoI reporting gives ReportSubject.CON/.IND_Country_FrameworkCodeModuleVersion_Module_ReferenceDate_CreationTimestamp.zip, with DORA010100 as the framework and module version code.
The failure pattern is usually mundane. A ZIP built for one module, a report.json extending another, or an entry point copied from an outdated package will typically fail before any useful business validation starts. Teams then spend time reading downstream messages that were caused by an upstream package mismatch.
Why control files fail packages early
parameters.csv and FilingIndicators.csv sit in that same critical path under EBA Filing Rules v5.5. parameters.csv carries package-level reporting context, including the entity reference used for the submission, so a mismatch there can make a technically neat package internally inconsistent.
Filing indicators tell the receiver which templates the package is declaring for validation. If those indicators do not match the actual content, the receiver validates the wrong scope, or fails the package before the data review gets anywhere useful.
The four keys are where integration starts to fray
Where joins actually fail
The RoI is filed as open tables, but the implementing technical standards (ITS) instructions make clear that it is validated as a joined dataset. In practice, four values do most of the linking work across the package:
- contractual arrangement reference number
- relevant entity or provider identifier
- function identifier
- type of ICT service
Those are the fields that let separate tables behave like one report, and they are also the fields most likely to create integration failures when they drift across templates. That is the submission-facing reason how identifiers are reused across tables to make the dataset joinable matters so much.
Under the linked-template logic in the ITS, some records only stay unambiguous when the identifier combinations required across those related tables remain consistent.
Once those combinations drift, the rest of the package no longer has one clean row to attach to.
Illustrative scenario
One broken provider ID, many downstream errors
Assume B_02.02 contains one contractual arrangement reference number, one provider identifier, one function identifier and one ICT service type.
The linked provider table is meant to carry that same provider identifier for the same chain of records. If the B_02.02 row contains <provider LEI A> and the linked provider row contains <provider LEI B> for what is supposed to be the same provider, the first join fails there.
The validation effect is predictable: foreign-key errors then appear in dependent records built on that provider and contract combination.
The sensible diagnostic move is to start with that first broken join, not the longer downstream error file.
Ownership breaks the joins before submission
This is also where the ownership problem usually becomes visible.
Contract reference numbers are often maintained close to procurement or outsourcing records, provider identifiers tend to sit with vendor master data, and function identifiers are usually shaped by business and risk teams.
Submission failure is often the moment those groups discover they were not working from one controlled dataset, even though the reporting package assumes exactly that.
Identifier choices become submission failures very quickly
The identifier decision sequence
The identifier rules are tighter than many institutions expect. Under the fill-in instructions in Annex II to Commission Implementing Regulation (EU) 2024/2956, legal persons established in the Union are identified with Legal Entity Identifier (LEI) or European Unique Identifier (EUID) where the field permits it. Legal persons outside the Union are identified with LEI.
Alternative identifiers such as national ID, passport number, VAT number or corporate registration number are reserved for natural persons acting in business capacity.
That gives a workable decision sequence. First determine whether the ICT provider is a legal person or an individual acting in business capacity. Then determine whether the legal person is established in the Union. Only then does the allowed identifier set become clear.
Weak identifier discipline shows up fast in submission. The FAQ’s rule on missing key data says key fields cannot be left blank and that “Not Applicable” should be used where the framework allows it for a primary-key field. A blank value does not just weaken the record, but it breaks the join.
Third-country providers and missing LEIs
Third-country providers are where this usually becomes uncomfortable.
The FAQ’s clarification on non-EU provider identifiers explains that if the LEI for a non-EU legal person or its ultimate parent is unavailable, institutions still need a usable key so the package can load and the relationships across tables remain intact.
That may get the file through reception, but it still leaves a data-quality issue once supervisors aggregate providers and group structures for dependency and concentration analysis. For institutions still working through those fields, which mandatory fields tend to drift and break submissions is the deeper view.
Empty tables are allowed. An empty submission is not.
This is one of the rules teams misread because the wording feels permissive until it is applied. Empty table files are allowed where there is genuinely nothing to report for that table. But the FAQ’s clarification that template B_01.02 cannot be left empty closes off the most common misunderstanding: even on an individual basis, the reporting financial entity still has to appear there.
That requirement makes more sense in the wider RoI operating model, where entity context is part of what supervisors are trying to aggregate.
Validation sequence: where failures actually start
This part is often underestimated early in projects. Institutions talk about “validation” as if it were one event, when the FAQ’s three-layer validation sequence splits it into three stages: the technical layer first, then Data Point Model (DPM) validations and business checks, and finally external LEI and EUID checks.
The distinction is operationally important. Technical rejection means the package was not ingested. Validation failure means the package was ingested and then failed DPM, business or external identifier checks. Teams that blur those two states usually waste time fixing the wrong thing.
Case differences alone are enough to fail ingestion or break joins. This is exactly where spreadsheet processes fail to maintain consistent identifiers and keys.
Copla Registry
Move beyond spreadsheets for DORA RoI
Spreadsheets struggle with the RoI’s relational structure and validation rules. Copla Registry provides a structured environment for maintaining the register and generating ESA-ready outputs.

Feedback handling is a control process
What comes back in the feedback package
The feedback loop is where weak submission processes become obvious. The EBA’s explanation of RoI validation feedback files describes the response package as a ZIP containing instance-status.csv and, where relevant, detailed-feedback.csv.
That is enough to define a disciplined intake process: parse the response automatically, classify the issue by validation stage, route it to the right owner, regenerate the full package and keep the resubmission trail clean.
The pressure does not sit only in initial data collection. It reappears when the package has to survive reception, integration, validation feedback and regeneration without losing control of versions or fixes. Those validation and resubmission cycles extend RoI delivery timelines.
Competent authorities still shape the submission path
There is also a practical submission constraint institutions need to remember.
The FAQ’s description of reporting flows through competent authorities makes clear that collection still runs through competent authorities first, with the authorities then reporting to the ESAs.
The validation logic is aligned, but portal behaviour, messaging and first-line workflow can still differ by authority.
Do not rely on dry-run tooling
One further point is worth keeping blunt. The FAQ’s answer on the 2024 dry-run conversion tool says that tool was provided for the dry run only and is not maintained for official reporting. A live process that still depends on dry-run tooling is already exposed to avoidable submission risk.
7 pre-flight checks before submission
Before submitting, run these checks:
1. Build the ZIP as a reporting package, with the correct root folder, META-INF/reportPackage.json, reports/report.json, parameters.csv, FilingIndicators.csv and the table CSVs.
2. Confirm the ZIP naming convention exactly, including reporting subject, IND or CON, country, framework and module code, reference date and creation timestamp.
3. Confirm that report.json points to the correct published DORA entry point for the module and version being used.
4. Validate parameters.csv and FilingIndicators.csv before spending time on business data.
5. Enforce UTF-8, delimiter and quoting rules, exact filenames, exact column headers and case sensitivity.
6. Enforce key discipline and referential integrity across the package: no empty key values, no accidental duplicate composite keys, “Not Applicable” only where the framework permits it, and clean alignment across contractual arrangement, provider identifier, function identifier and ICT service type.
7. Triage feedback in validation order: technical reception first, then DPM and business checks, then external LEI and EUID issues.
Earlier checks on package structure, version alignment and key integrity reduce avoidable technical rejects and make resubmissions easier to control. That is the difference that matters here: not whether the register exists somewhere internally, but whether it can be submitted, validated and worked back through correction cycles without the whole process becoming guesswork.




